Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur en big data
Niveau 2
Répond à des critères de performance élevés et a fait ses preuves en matière de satisfaction clients.
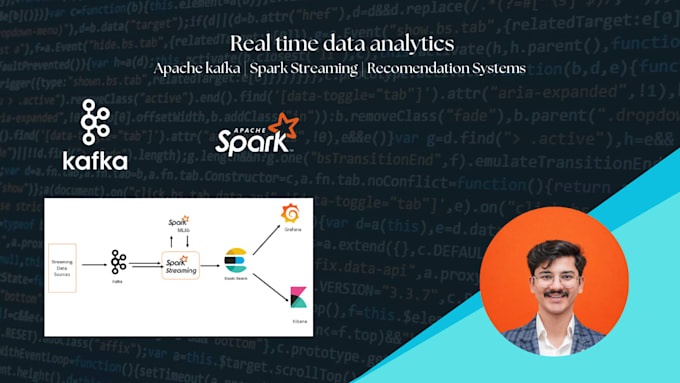
Les applications modernes génèrent d'énormes flux de données en temps réel provenant de sites web, d'applications mobiles, d'appareils IoT et de plateformes cloud. Traiter ces données efficacement nécessite des architectures de streaming évolutives et des pipelines de données fiables.
Je suis un ingénieur de données spécialisé dans les systèmes big data et le traitement en temps réel, et je vous aiderai à concevoir et à mettre en œuvre des pipelines de streaming haute performance utilisant des technologies comme Apache Kafka et Apache Spark.
J'ai de l'expérience dans la construction de systèmes de données distribués et de pipelines analytiques à grande échelle, y compris un système de recommandation musicale en temps réel traitant plus de 100 Go de données de streaming avec Hadoop et Spark, et des pipelines ETL en temps réel avec entreposage de données pour l'analyse d'entreprise.
Technologies
Cas d'utilisation
Je me concentre sur la construction de pipelines de streaming évolutifs, fiables et prêts pour la production qui transforment les données en direct en insights exploitables.
Contactez-moi avant de passer commande pour discuter de vos besoins.