Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Transformer vos idées en solutions, sites web et croissance numérique !
VOS DONNÉES SONT-ELLES RESTÉES DANS LE PASSÉ ? IL EST TEMPS D'Y ALLER RÉELLEMENT
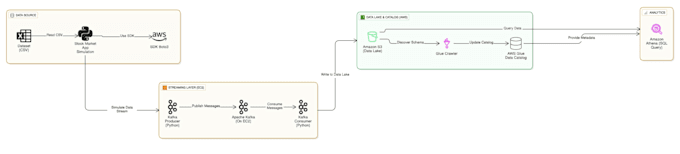
Je suis un Cloud Data Engineer spécialisé, expérimenté dans la création d'architectures de données performantes. Récemment, j'ai conçu un Pipeline de streaming en temps réel pour le marché boursier capable de gérer une forte volatilité des données en utilisant Apache Kafka et AWS, et je vais réaliser cette même qualité d'entreprise pour votre activité.
Mon stack technique :
Ce que je vais construire pour vous :
Pourquoi me choisir ? Contrairement à des développeurs génériques, je comprends les données financières. Mon code est modulaire, bien documenté et prêt pour la production.
️
VEUILLEZ M'ENVOYER UN MESSAGE AVANT DE COMMANDER pour discuter de vos besoins spécifiques en architecture !

Traduction automatique
Dois-je fournir mes propres identifiants AWS ?
Oui. Pour que je puisse déployer le pipeline, j'aurai besoin d'un utilisateur IAM avec les permissions appropriées (accès S3, EC2, Redshift). Je peux vous guider pour créer cela en toute sécurité sans partager votre mot de passe root.
Le fonctionnement de ce pipeline sera-t-il coûteux sur ma facture AWS ?
Je conçois pour l'efficacité des coûts. J'utilise des ressources éligibles au "Free Tier" (comme des instances t2.micro pour Kafka) lorsque c'est possible et je configure des politiques de cycle de vie S3 pour archiver les anciennes données, afin de maintenir vos coûts de fonctionnement faibles.
Proposez-vous un support si le pipeline tombe en panne après livraison ?
Oui. Les packages Standard et Premium incluent une période de support après livraison (5-7 jours) pour corriger tout bug lié à mon code. Je fournis également un guide pour redémarrer les services si nécessaire.
Quelle API utilisez-vous pour récupérer les données du marché boursier ?
J'utilise généralement yfinance ou Alpha Vantage pour la simulation en temps réel. Cependant, le pipeline est modulaire. Je peux remplacer le script "Producer" pour ingérer des données depuis toute API financière que vous préférez (par exemple Polygon.io ou IEX Cloud).
Comment gérez-vous la forte volatilité ou les pics de données sur le marché ?
L'architecture utilise Apache Kafka comme tampon. Si le marché boursier envoie un pic massif de données, Kafka le met en file d'attente en toute sécurité jusqu'à ce que les consommateurs (Spark/Python) puissent le traiter, garantissant qu'aucune donnée ne soit perdue lors d'une forte affluence.
Pourquoi utilisez-vous Zookeeper dans cette architecture ?
Zookeeper gère les brokers Kafka. Il suit l'état des nœuds Kafka et surveille quels sujets et partitions sont actifs. Il est essentiel pour la tolérance aux fautes du cluster de streaming.
À quel point le traitement des données est-il "en temps réel" ?
La latence est extrêmement faible. Le Kafka Producer récupère instantanément les prix des actions, et le Consumer les traite en quasi temps réel (généralement en millisecondes ou quelques secondes), ce qui le rend adapté pour des tableaux de bord en direct.
Dans quel format enregistrez-vous les données dans S3 ?
En général, les données sont enregistrées au format Parquet ou CSV. Parquet est fortement recommandé pour les données financières car il est compressé et en colonnes, ce qui rend les requêtes via AWS Athena ou Redshift beaucoup plus rapides et économiques.
Ce pipeline gère-t-il les données en double ?
Oui. J'implémente une logique dans le script du Consumer (avec Spark ou Python Pandas) pour supprimer les doublons basés sur les horodatages et les identifiants d'actions avant de charger les données nettoyées dans votre base.
Puis-je connecter ce pipeline à un tableau de bord comme PowerBI ou Tableau ?
Absolument. Étant donné que les données finales sont stockées dans AWS Redshift ou S3, vous pouvez connecter directement PowerBI, Tableau ou AWS QuickSight pour visualiser les tendances en direct des actions.