Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Science des données et intelligence artificielle
Vous cherchez plus qu’un simple script NLP de base ?
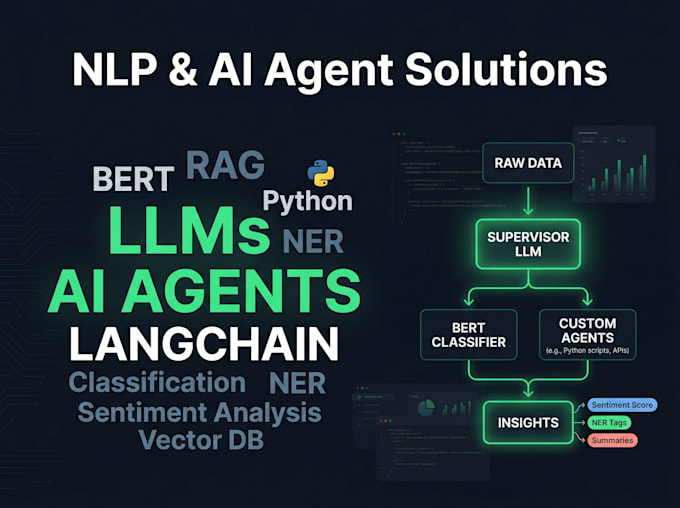
Je crée des systèmes de traitement de texte intelligents de bout en bout, allant des pipelines NLP classiques aux modèles BERT fine-tunés et aux agents IA prêts pour la production, alimentés par LangGraph et LangChain. Que vous ayez besoin d’un classificateur de sentiment, d’un chatbot spécifique à un domaine ou d’un système LLM multi-agent complet, je fournis des solutions propres, documentées et déployables.
Ce que je propose :
1. NLP & Analyse de texte
Prétraitement du texte : tokenisation, suppression des stopwords, lemmatisation (spaCy / NLTK)
Classification de texte & Analyse de sentiment (Naive Bayes, SVM, Régression logistique)
Reconnaissance d’entités nommées (NER), extraction de mots-clés et de phrases-clés
TF-IDF, analyse N-gram, fréquence des mots, réseaux de co-occurrence
Modélisation de sujets : LDA, NMF, BERTopic
Résumé de texte & Similarité sémantique
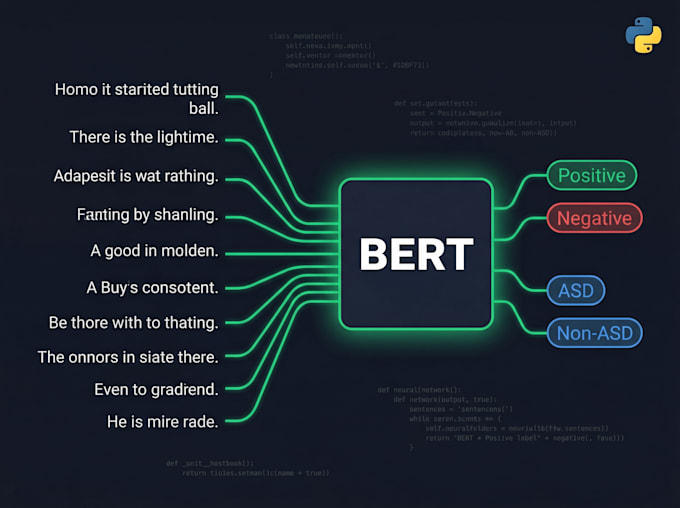
2. Fine-tuning de BERT & Transformer
Fine-tune BERT, RoBERTa, DistilBERT, AraBERT sur votre jeu de données personnalisé
Classification de séquences, classification de tokens, réponse à des questions
Courbes d’entraînement, rapport d’évaluation (précision, F1, matrice de confusion)
Sauvegarde & exportation des poids du modèle (format HuggingFace, .pth, .zip)
3. Agents IA & Solutions LLM
Orchestration multi-agent avec LangGraph, domaine spécifique



Langage de programmation:
Python
•
MATLAB
•
SQL
•
Colab
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
APIs:
Autres
Outils:
Jupyter Notebook
•
opencv
•
tensorflow
•
Excel
•
Colab
Traduction automatique
Q1 : Avec quel type de données textuelles pouvez-vous travailler ?
Tout domaine — texte médical/clinique, avis clients, publications sur les réseaux sociaux, commentaires YouTube, documents juridiques, articles académiques, rapports financiers, réponses à des enquêtes. Si vous avez du texte, je peux en faire quelque chose.
Q2 : Ai-je besoin d’un jeu de données étiqueté pour la classification ?
Pour les tâches supervisées (classification, sentiment) — oui, des données étiquetées sont nécessaires. Pour les tâches non supervisées (modélisation de sujets, clustering, extraction de mots-clés) — du texte brut suffit. Je peux aussi vous conseiller sur la stratégie d’étiquetage si vous partez de zéro.
Q3 : Pouvez-vous créer un système RAG pour mes documents ou ma base de connaissances ?
Oui — cela fait partie du package Premium. Je vais mettre en place un magasin de vecteurs (FAISS ou Chroma), le connecter à vos documents, et construire un pipeline de récupération LangChain pour que votre LLM réponde aux questions uniquement à partir de vos données.
Q4 : Avec quels LLM travaillez-vous ?
OpenAI GPT-3.5 / GPT-4, Groq (LLaMA 3, Mixtral), Google Gemini, Mistral. Je peux utiliser ceux que vous préférez ou pour lesquels vous avez déjà un accès API. Je peux aussi utiliser des modèles open-source locaux via Ollama si vous souhaitez zéro coût API.
Q5 : Pourrai-je exécuter et modifier le code moi-même ?
Absolument. Tous les livrables sont des notebooks Jupyter/Colab propres, bien commentés. Je code pour les humains, pas seulement pour les machines. Vous comprendrez chaque étape, et je serai heureux d’expliquer tout après la livraison.
Q6 : Pouvez-vous déployer le modèle ou l’agent en tant qu’API ou application web ?
Un déploiement basique (point de terminaison FastAPI ou application Streamlit) peut être ajouté en option. Pour un déploiement complet dans le cloud (AWS, GCP, Hugging Face Spaces), contactez-moi avant de commander pour un devis personnalisé.