Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur principal des données
Je suis un ingénieur de données senior avec plus de 6 ans d'expérience dans la conception de pipelines de données évolutifs et de plateformes de données cloud. Je me spécialise dans la création de workflows ETL fiables, la transformation de données brutes en ensembles de données structurés, et la mise en place de systèmes de données prêts pour l’analyse.
Je peux vous aider avec :
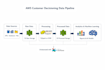
-Développement de pipelines ETL en utilisant Python, SQL et Pyspark
-Ingestion de données depuis API, fichiers et bases de données
-Transformation et optimisation des données
-Pipelines de données cloud utilisant AWS (S3, EMR, Redshift, Glue, Kinesis, Athena)
-Architecture Lakehouse (couches Bronze, Silver, Gold)
-Intégration de data warehouse et optimisation des performances
Je me concentre sur la création de pipelines de données efficaces, évolutifs et prêtes pour la production qui supportent l’analyse, le reporting et les workflows de machine learning.
Si vous avez besoin d’aide pour concevoir ou améliorer votre pipeline de données ou plateforme de données, n’hésitez pas à me contacter avant de passer commande.

Type de projet:
New Build
