Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD



Traduction automatique
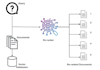
Ce que vous obtenez :
Infrastructure RAG AI entièrement configurée (Retriever + LLM + Vector Store + couche API)
Déploiement sur AWS, Google Cloud (GCP) ou Microsoft Azure
Infrastructure gérée via Kubernetes (EKS, GKE ou AKS)
Intégration avec des outils comme LangChain, LLamaIndex, Pinecone, Weaviate, FAISS ou votre base de données vectorielle préférée
Pipeline CI/CD pour des déploiements évolutifs et reproductibles
Optionnel : configuration de API Gateway, authentification, surveillance et journalisation
️
Cas d’utilisation :
Pile technologique (modifiable selon vos besoins) :
Pourquoi me choisir ?
Je suis ingénieur DevOps + IA avec une expérience pratique dans la mise en place d’architectures RAG cloud-native, évolutives et économiques pour startups et entreprises. Je travaille en étroite collaboration avec vous pour fournir des solutions sur mesure, sécurisées et prêtes pour l’avenir.
Software Engineer : DevOps and Cloud Consultant
Langues
Traduction automatique
Traduction automatique
Q1 : Qu’est-ce que RAG AI, et pourquoi devrais-je l’utiliser ?
R : RAG (Retrieval-Augmented Generation) est une architecture IA puissante qui combine de grands modèles de langage (LLMs) avec des sources de connaissances externes (comme des bases de données vectorielles) pour des réponses plus précises, à jour et contextuelles. Idéal pour chatbots, recherche de documents et assistants IA.
Q2 : Pouvez-vous déployer sur n’importe quel fournisseur cloud ?
Oui ! Je supporte AWS, Google Cloud Platform (GCP) et Microsoft Azure. J’utilise également Kubernetes (EKS, GKE ou AKS) pour un déploiement évolutif et cloud-native.
Q3 : Quels composants sont inclus dans le déploiement ?
Un déploiement typique comprend : - Intégration LLM (OpenAI, Hugging Face, etc.) - Base de données vectorielle (ex : FAISS, Pinecone, Chroma) - Logique API et récupération (LangChain ou LlamaIndex) - CI/CD (optionnel) - Orchestration Kubernetes - Surveillance et journalisation (sur demande)
Q4 : Pouvez-vous configurer cela pour des environnements sandbox/test ?
Absolument ! Je peux mettre en place des environnements légers pour l’expérimentation et la R&D, ainsi que des systèmes sécurisés et prêts pour la production.
Q5 : Pourrai-je assurer la maintenance du système par la suite ?
Oui. Je fournis la documentation, des walkthroughs, et éventuellement une démonstration vidéo pour aider votre équipe à gérer le système de manière autonome.
Q6 : Puis-je demander une configuration personnalisée ?
Certainement. Chaque entreprise a des besoins uniques — contactez-moi avant de passer commande, et je créerai une configuration spécialement pour vous.


