Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Faisons en sorte que le machine learning serve vos objectifs !
À propos de moi
Bonjour ! Je suis Sivanandham, un spécialiste en apprentissage automatique avec une expérience confirmée en prévision financière, prédiction du marché boursier et automatisation basée sur les données. Avec plus de 2 ans d’expérience pratique en Intelligence Artificielle, Apprentissage Automatique, Analyse de Données, Science des Données et systèmes d’IA.
J’ai réalisé plus de 25 projets ML concrets qui ont réellement résolu des problèmes commerciaux, pas seulement des démos académiques.
Services que je propose :
Développement de modèles ML : Classification, Régression
Étapes du pipeline : ingestion de données, nettoyage et prétraitement, ingénierie des caractéristiques, entraînement du modèle, réglage des hyperparamètres, validation et prédiction
Entraînement et évaluation du modèle : Précision, F1-Score, ROC-AUC
Optimisation du modèle : métriques d’évaluation, GridSearchCV
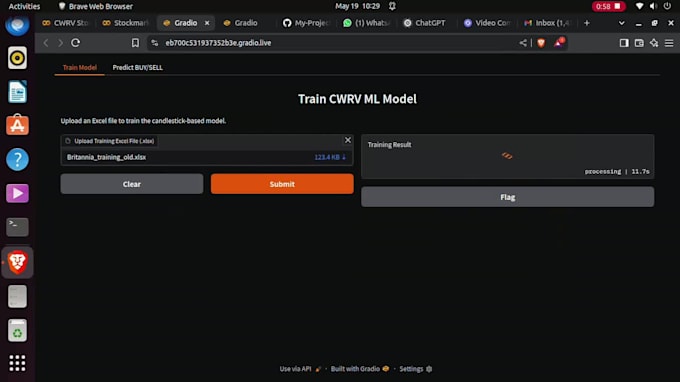
Déploiement du modèle : applications basées sur Gradio, déploiement local
Outils et technologies :
Langages et bibliothèques : Python, Pandas, NumPy, Matplotlib, Seaborn, Gradio, Excel, Scikit learn
Algorithmes ML : arbres de décision, machine à vecteurs de support (SVM), régression logistique/linéaire, gradient boosting, validation croisée, recherche par grille
Contrôle de version : GitHub
Conseil : Avant de passer commande, envoyez-moi un message avec votre dataset, vos objectifs et vos attentes afin que je vous propose le plan et le calendrier adaptés.




Langage de programmation:
Python
•
Colab
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
APIs:
Google Cloud Vision API
Outils:
Jupyter Notebook
•
opencv
•
Excel
•
MLflow
•
Colab
Traduction automatique
Pouvez-vous travailler avec mon jeu de données brut ou doit-il être nettoyé ?
Oui, je peux travailler avec des données brutes. Je propose un nettoyage complet des données (ETL), un prétraitement et une transformation pour rendre votre jeu de données prêt pour le ML — y compris la gestion des valeurs manquantes, des valeurs aberrantes et des problèmes de formatage.
Quels livrables vais-je recevoir ?
Vous recevrez un code Python (propre et commenté), des visualisations de performance (matrice de confusion, courbe ROC, importance des caractéristiques), une explication du modèle et des fichiers prêts pour le déploiement.
Comment garantissez-vous que le modèle fonctionne bien ?
J'utilise des techniques éprouvées comme la validation croisée, la séparation train-test, l'analyse biais-variance et le réglage des hyperparamètres (GridSearchCV) pour construire des modèles optimisés et robustes.
Comment choisir entre les packages Basic, Standard et Advanced ?
● Basic est idéal pour des cas d'utilisation simples ou pour l'apprentissage des débutants. ● Standard inclut le prétraitement complet, la gestion du déséquilibre et le réglage — parfait pour les petites entreprises. ● Advanced propose des modèles prêts pour la production, la comparaison de plusieurs algorithmes et une interface utilisateur adaptée aux professionnels et aux projets de recherche.
Mes données resteront-elles privées ?
Absolument. Vos données sont traitées comme confidentielles et ne seront jamais partagées ou réutilisées.
Comment puis-je être sûr que votre service est fiable ?
Avec plus de 25 projets ML concrets, une formation avancée (certification IA de 6 mois de Novi Tech) et des résultats commerciaux prouvés (par exemple, une croissance de 2166 % grâce aux insights ML), je fournis des modèles structurés, explicables et impactants, adaptés à vos objectifs.
Pouvez-vous fournir une documentation ou une explication sous forme de notebook ?
Oui. Je peux livrer le projet sous forme de Jupyter Notebook ou Google Colab avec des explications étape par étape, des commentaires et des visualisations pour une meilleure compréhension et réutilisation.
Quelle taille de jeu de données pouvez-vous gérer ?
Je peux travailler efficacement avec des jeux de données petits à moyens. Des offres personnalisées peuvent être proposées pour assurer une performance optimisée en utilisant des techniques de gestion efficace de la mémoire.
Quels services spécifiques de data science proposez-vous ?
Je propose une gamme de services incluant le nettoyage et le prétraitement des données, l'analyse exploratoire, la modélisation prédictive, le réglage fin, le développement d'algorithmes d'apprentissage automatique, la visualisation des données et des insights exploitables.
Comment garantissez-vous la confidentialité et la sécurité de mes données ?
Vos données sont traitées avec une confidentialité stricte. Toutes les données sensibles sont traitées dans des environnements sécurisés et ne seront pas téléchargées en ligne ni traitées via des plateformes en ligne : vos données sont accessibles uniquement par vous et le Jupyter Notebook tournant sur mon ordinateur portable.