Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD



Traduction automatique
Arrêtez d'utiliser des wrappers AI basiques. Offrez à votre entreprise un "Cerveau" qui se souvient réellement.
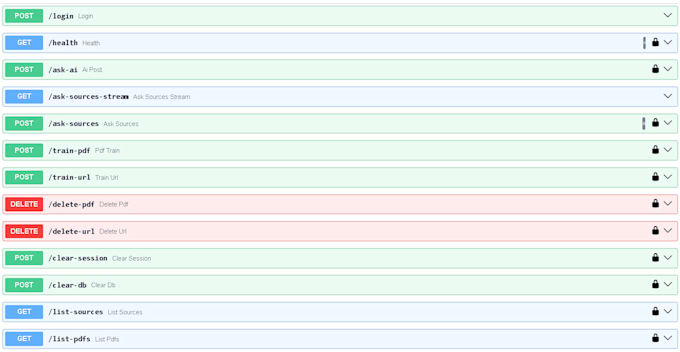
Je vais créer un système professionnel, conteneurisé, Retrieval-Augmented Generation (RAG) qui vous permet de discuter avec vos PDFs privés et données de site web avec 99,9 % de précision. Contrairement aux bots standards, ce système utilise Cross-Encoder Reranking pour garantir que l'IA ne "hallucine" jamais sur vos données.
Ce qui est inclus :
️ La stack technologique :
Contactez-moi aujourd'hui pour une démo personnalisée du système !
Professional Software Engineer
Langues
Traduction automatique
Traduction automatique
Mes données seront-elles utilisées pour entraîner des modèles AI publics (comme ChatGPT) ?
Non. Grâce à l'architecture RAG (Retrieval-Augmented Generation), vos données restent dans votre base de vecteurs privée. Le LLM ne "lit" que les parties pertinentes pour répondre à votre requête spécifique et ne "apprend" pas d'elles de façon permanente.
Quels formats de fichiers le système supporte-t-il ?
Par défaut, il supporte les PDFs. Cependant, le système est modulaire et peut être étendu pour supporter les fichiers TXT, DOCX et CSV si nécessaire.
Ai-je besoin de mes propres clés API ?
Oui. Vous aurez besoin d'une clé API gratuite Groq ou OpenAI. Cela vous permet de contrôler entièrement vos coûts et vos données. Je vous montrerai exactement où les obtenir.
Puis-je héberger cela sur mon propre serveur d'entreprise ?
Absolument. Si vous choisissez le niveau Premium, je fournis une suite Docker complète. Si votre serveur supporte Docker, vous pouvez lancer tout le système en une seule commande.
Y a-t-il une limite au nombre de PDFs/sites web que je peux uploader/entraîner ?
Le système est conçu pour évoluer. Pour une utilisation commerciale standard (des centaines de documents), il est extrêmement rapide. Pour des ensembles de données massifs (plus de 10 000 pages), nous pouvons discuter d'une configuration de base de données haute performance sur mesure.