Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur data, ETL, APIs et automatisation BI
Ce que je peux faire :
Connectivité complète aux sources de données (multi-source / pipelines complexes)
Intégration API + intégration de systèmes externes
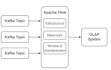
Fonctionnalités avancées de Flink (checkpointing, gestion d’état, fenêtres, jointures)
Optimisation du système et réglages de performance
Conseils en conception d’architecture
Formatage et nettoyage
Inclut le code source complet + documentation
« Ingénieur data absolument brillant. Il a mis en place notre pipeline de streaming Kafka vers Flink sans faute pour notre MVP. Le code était propre, bien documenté et livré à temps. »
-- David L., chef de projet technique
« Nous avions des difficultés avec la gestion d’état et les fenêtres dans notre processus ETL en temps réel. Il a non seulement corrigé nos bugs, mais aussi optimisé toute l’architecture Flink. Très recommandé pour des flux de données complexes ! »
-- Alex R., architecte de données
« Rapide, professionnel, avec une expertise approfondie en Apache Flink. Il a intégré sans problème plusieurs API externes dans notre flux de données et a parfaitement ajusté la performance pour la production. Je ferai à nouveau appel à lui. »
-- Sarah M., fondatrice de startup



Expertise:
Big data
•
Flux de données
•
etl
Technologie:
Apache Kafka
•
Apache Spark
•
Java
•
Python
•
Scala
•
Autres


