Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
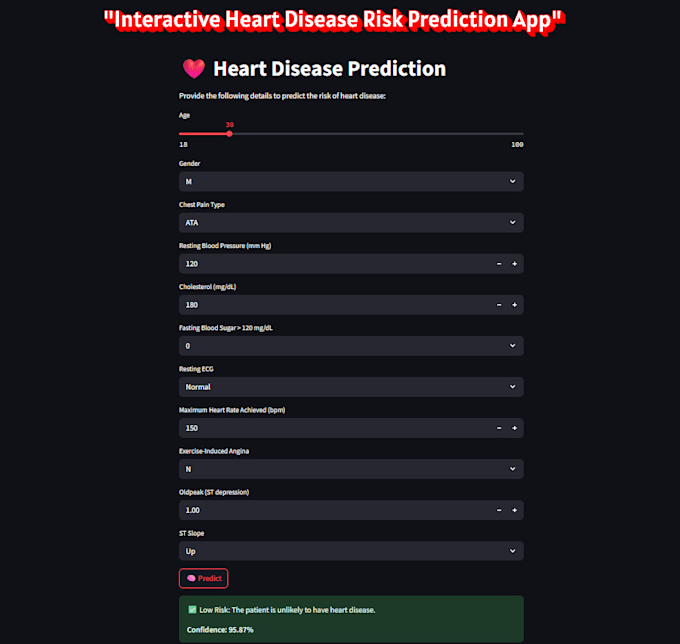
Nettoyez, analysez et visualisez vos données avec une seule solution
Je réaliserai une analyse complète des données et construirai des modèles d'apprentissage automatique pour vous aider à faire des prédictions précises basées sur les données en utilisant Python, Pandas et scikit-learn.
De la nettoyage des données, à l'analyse exploratoire (EDA), en passant par la gestion des valeurs manquantes, jusqu'à l'entraînement des modèles ML et leur déploiement avec Flask ou FastAPI, je propose des solutions d'apprentissage automatique de bout en bout adaptées à vos besoins.
Ce que vous obtiendrez :


Technologie:
Excel
•
Google Sheets
•
Python
•
SQL
Traduction automatique
Q : Quel type de données pouvez-vous traiter ?
R : Je peux travailler avec des ensembles de données structurés tels que CSV, Excel, JSON ou bases de données SQL. Que ce soit dans les domaines des ventes, de la santé, du marketing, de la finance ou autres — je peux aider à nettoyer, analyser et modéliser vos données.
Q : Quels modèles d'apprentissage automatique utilisez-vous ?
R : J'utilise des modèles ML populaires tels que la régression linéaire, la régression logistique, les arbres de décision, la forêt aléatoire, XGBoost, les machines à vecteurs de support (SVM), KNN, et plus encore — en fonction de vos données et objectifs.
Q : Quels outils et bibliothèques utilisez-vous ?
R : J'utilise principalement Python avec des bibliothèques telles que Pandas, NumPy, matplotlib, seaborn, scikit-learn, XGBoost, et pour le déploiement : Flask ou FastAPI.
Q : Pouvez-vous m'expliquer les résultats ?
R : Absolument ! Je fournirai des visualisations claires, des rapports synthétiques et des explications des résultats du modèle pour que vous compreniez ce que fait le modèle et ce que signifient les prédictions.
Q : Pouvez-vous déployer le modèle en tant qu'API ?
R : Oui, dans le pack Gold, j'offre une intégration API avec Flask ou FastAPI pour que votre modèle puisse être utilisé dans des applications ou sites web.
Q : Vais-je recevoir le code source et les fichiers du modèle ?
R : Oui, je livrerai le notebook Jupyter complet, le fichier du modèle entraîné (.pkl ou .joblib), et tout autre fichier supplémentaire comme des rapports ou visualisations — selon le pack que vous aurez choisi.
Q : Pouvez-vous gérer les valeurs manquantes et les valeurs aberrantes ?
R : Oui, j'identifierai et traiterai les données manquantes et les valeurs aberrantes en utilisant les meilleures pratiques pour garantir que votre ensemble de données soit propre et prêt pour la modélisation.