Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur data, pipelines ETL, Spark et expert en entrepôt de données cloud
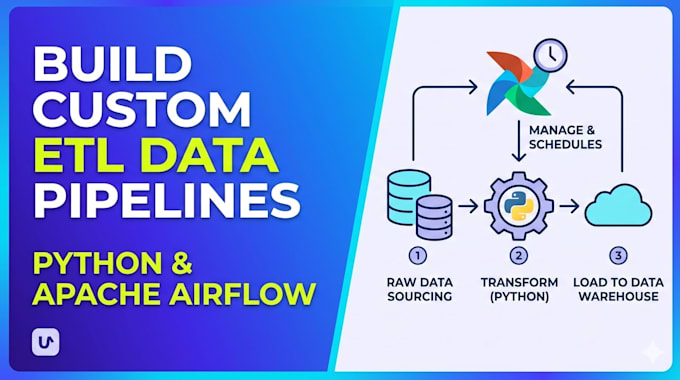
Vous avez du mal avec des transferts de données manuels, des scripts cassés ou des pipelines de données peu fiables ? Je vais créer pour vous un pipeline ETL prêt pour la production qui extrait, transforme et charge vos données automatiquement, vous faisant gagner des heures de travail manuel chaque semaine.
Ce que je propose :
- Pipeline ETL personnalisé développé en Python avec un code propre et documenté
- DAG Apache Airflow pour la planification automatisée et la surveillance
- Support pour toutes les principales sources de données : bases de données (PostgreSQL, MySQL), APIs, CSV/Excel, S3, Google Sheets
- Logique de transformation et de nettoyage des données adaptée à vos règles métier
- Gestion des erreurs, logique de réessai et alertes par email/Slack en cas d’échec
- Déploiement sur votre infrastructure cloud (AWS, GCP, Azure) ou serveur local
- Documentation complète pour que votre équipe puisse l’entretenir de manière autonome
Technologies que j’utilise : Python, Apache Airflow, Apache Spark, Pandas, SQLAlchemy, AWS Glue, AWS Lambda, S3, PostgreSQL, MySQL, BigQuery, Snowflake.
Destiné à :
- Startups créant leur premier pipeline de données automatisé
- Entreprises migrantes de workflows manuels Excel/CSV vers l’automatisation ETL
- Équipes remplaçant un pipeline de données legacy cassé ou lent
- Entreprises nécessitant un pipeline d’ingestion de données pour Snowflake ou BigQuery

Traduction automatique
Quelles sources de données pouvez-vous connecter ?
Quelles sources de données pouvez-vous connecter ? Je peux me connecter à n’importe quelle base SQL (PostgreSQL, MySQL, MSSQL), APIs REST, fichiers CSV/JSON/Excel, stockage cloud (S3, GCS), Google Sheets, et outils SaaS comme Salesforce ou HubSpot via des connecteurs.
Ai-je besoin d’un compte cloud ?
Pour le déploiement cloud, j’aurai besoin d’accéder à votre compte AWS/GCP/Azure. Pour les déploiements locaux, je n’ai besoin que d’un accès SSH au serveur. Je peux également fournir une solution basée sur Docker que vous pouvez exécuter partout.
Pourrai-je maintenir le pipeline moi-même ?
Oui. Chaque pipeline que je fournis est accompagné d’une documentation complète, de commentaires dans le code et d’une vidéo explicative pour que votre équipe puisse le maintenir et le faire évoluer sans moi.
Que faire si j'ai besoin de modifications après la livraison ?
Les packages Standard et Premium incluent des révisions. Je propose également un package de maintenance payant si vous souhaitez un support continu.
Combien de temps prend un pipeline ETL typique ?
Combien de temps prend un pipeline ETL typique ? Un pipeline simple à source unique prend 2 à 3 jours. Un pipeline multi-sources avec planification Airflow prend 4 à 6 jours. Je confirme toujours le délai avant votre commande.
