Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD




Traduction automatique
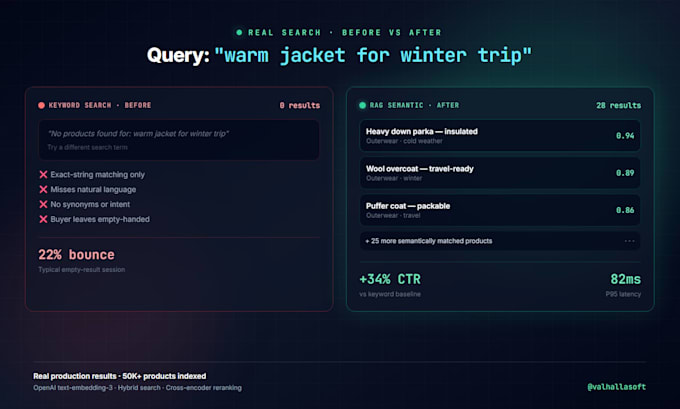
Arrêtez de perdre des ventes à cause d'une mauvaise recherche.
Si la recherche de votre commerce en ligne ne renvoie aucun résultat lorsque les acheteurs tapent des requêtes naturelles au lieu de références exactes, vous laissez de l'argent sur la table. Je mets en place une recherche RAG et sémantique de niveau production qui comprend l'intention, pas seulement les mots-clés.
Exemple concret : je dirige actuellement la migration de la recherche AI pour l'un des plus grands détaillants d'Amérique latine (plus de 200 magasins, plus d'un million d'utilisateurs quotidiens, plus de 50 000 produits), en remplaçant l'API Google Search par un système basé sur RAG, prévu pour économiser 500 000 dollars par an.
Ce que vous obtenez :
Stack : Python (FastAPI), OpenAI / sentence-transformers, AWS, Docker, Kubernetes.
Pourquoi moi : plus de 10 ans à construire des backends en production à grande échelle. Ingénieur plateforme senior avec responsabilité sur l'architecture interéquipes. Je livre des livrables testés et documentés pour que votre équipe prenne en main le système après la livraison.
Contactez-moi avec votre stack, la taille de votre catalogue, et ce qui ne fonctionne pas dans votre recherche actuelle. Je réponds en moins d'une heure avec des étapes concrètes.
Senior RAG and AI Search Engineer for Backend at Scale
Langues
Traduction automatique
Traduction automatique
Quelle base de données vectorielle devrais-je utiliser ?
Cela dépend de l'échelle, du coût et des contraintes opérationnelles. Je vous aide à choisir entre Pinecone (géré), Weaviate (auto-hébergé), Qdrant (open source) et pgvector (pas d'infrastructure nouvelle). Le package Revue d'architecture inclut cette décision.
Combien coûte l'API d'intégration d'embeddings OpenAI ?
Pour 50 000 produits avec OpenAI text-embedding-3-small, le coût initial d'indexation est d'environ 1 à 2 dollars US. L'embedding pour chaque requête coûte environ 0,00002 dollar. Je fournis des projections de coûts dans les packages Standard et Premium.
Pouvez-vous intégrer avec mon backend de recherche existant ?
Oui. La recherche hybride combinant votre backend de mots-clés existant avec des vecteurs sémantiques dépasse généralement la recherche purement sémantique. J'intègre avec Elasticsearch, Algolia, Typesense, OpenSearch et Meilisearch.