Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Data Scientist, ingénieur en solutions d'IA, spécialiste en IA agentique
Des données désordonnées vous ralentissent-elles ? La plupart des projets de Data Science échouent en raison de la mauvaise qualité des données. Je suis là pour vous aider. Je propose des services experts de nettoyage de données, d’analyse exploratoire (EDA) et d’ingénierie des caractéristiques pour garantir que vos données soient précises, pertinentes et prêtes pour le modèle.
Ce que je propose :
1. Nettoyage professionnel des données
2. Analyse exploratoire approfondie (EDA)
3. Ingénierie avancée des caractéristiques
Outils & Technologies :
J’utilise Python avec des bibliothèques standards de l’industrie : Pandas, NumPy, Seaborn, Matplotlib et Scikit-learn.
Livrables : Vous recevrez un jeu de données nettoyé (CSV/Excel) et un notebook Jupyter entièrement documenté (.ipynb) avec tout le code et toutes les visualisations.
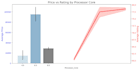
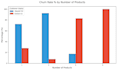


Traduction automatique
De quoi ai-je besoin pour commencer ?
Veuillez fournir votre jeu de données au format CSV, Excel ou SQL, accompagné d'une brève description de vos objectifs. Si vous avez des questions spécifiques auxquelles vous souhaitez que l'Exploratory Data Analysis (EDA) réponde, n'hésitez pas à les lister !
Quels outils utilisez-vous pour le nettoyage des données et l'EDA ?
J'utilise principalement Python avec des bibliothèques puissantes comme Pandas et NumPy pour la manipulation de données, et Matplotlib ou Seaborn pour des visualisations de données de haute qualité.
Pouvez-vous gérer des jeux de données très désordonnés avec des valeurs manquantes ?
Oui ! C'est ma spécialité. J'utilise des techniques d'imputation avancées (moyenne, médiane, mode ou remplissage prédictif) et la détection des valeurs aberrantes pour garantir que vos données soient cohérentes et prêtes pour l'analyse.
Qu'est-ce que la "Feature Engineering" et pourquoi en ai-je besoin ?
La "Feature Engineering" consiste à créer de nouvelles variables à partir de vos données brutes pour aider les modèles de Machine Learning à mieux performer. Par exemple, transformer une colonne "Date" en "Jour de la semaine" ou "Férié". Cela apporte une valeur ajoutée significative à vos modèles prédictifs.
Que signifie "100 items cleaned" dans vos packages ?
Dans la catégorie Data Cleaning, Fiverr fixe un minimum de 100 items. J'interprète ces "items" comme des points de données ou des lignes. Mon package Basic est conçu pour fournir un nettoyage et une EDA de haute qualité pour des jeux de données standard. Si votre fichier comporte plusieurs milliers de lignes, ne vous inquiétez pas — je peux le gérer dans le cadre du package indiqué.
Vais-je obtenir le code source ?
Absolument. Je livrerai un Jupyter Notebook (.ipynb) bien documenté ou un script Python afin que vous puissiez voir exactement comment les données ont été transformées et recréées à l'avenir.
Mes données sont-elles en sécurité avec vous ?
Oui, je prends la confidentialité des données très au sérieux. Vos données ne seront utilisées que dans le cadre du projet et seront supprimées de mon système une fois la commande terminée et acceptée.


