Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur de données spécialisé en pipelines ETL, Databricks, Azure et Power BI
Bonjour, je suis un consultant en ingénierie des données avec plus de 5 ans d'expérience dans la création de pipelines de données en production sur Databricks.
J'ai conçu de véritables charges de travail Databricks en production, notamment une plateforme de données client traitant de grands ensembles de données avec PySpark, Delta Live Tables et une architecture medallion. Je travaille quotidiennement sur Databricks, pas seulement comme un mot à la mode.
Ce que je vais réaliser pour vous :
Pourquoi travailler avec moi :
Pile technologique :
Avant de commander :
Contactez-moi avec vos exigences complètes.

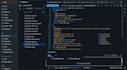
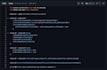
Destination Platform:
Databricks Lakehouse
Outils et plateformes:
Autres


