Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD




Traduction automatique
Avez-vous un ensemble de données et besoin d’un modèle ML fonctionnel qui résout
votre problème actuel ?
Je construis, entraîne et déploie des modèles d'apprentissage automatique adaptés à
vos données et votre objectif.
CE QUE JE CONSTRUIS :
- Classification (spam, fraude, churn, sentiment, image)
- Régression & prédiction (prix, demande, prévisions)
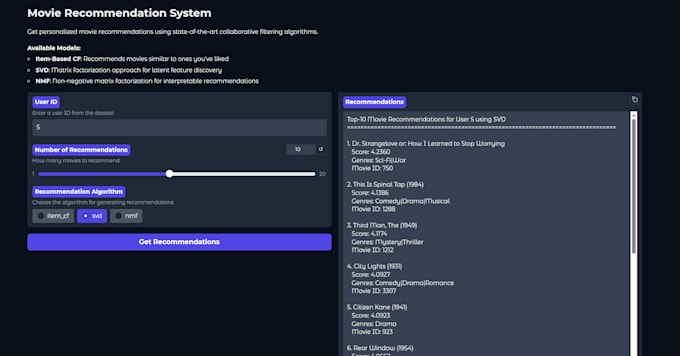
- Systèmes de recommandation (filtrage collaboratif, SVD, NMF)
- NLP (analyse de sentiment, classification de texte)
- Vision par ordinateur (classification d’image, CNN)
LIVRÉ & DÉPLOYÉ :
- Système de recommandation de films en ligne sur Hugging Face
- Classificateur d’images chat vs chien avec 96 % de précision, en ligne sur Hugging Face
- Classificateur de sentiment pour les critiques de jeux avec 82 % de précision
CE QUE VOUS RECEVEZ :
- Modèle entraîné avec toutes les métriques d’évaluation
- Notebook Jupyter propre avec pipeline complet
- Dépôt GitHub avec code documenté
- Déploiement sur Hugging Face (Standard & Premium)
TECHNOLOGIES :
Python, scikit-learn, TensorFlow, Keras, NLTK,
Pandas, Gradio, Hugging Face, PyTorch
IMPORTANT :
Le client doit fournir l’ensemble de données. Les commandes ne peuvent pas
commencer sans données.
Full Stack Developer, AI, ML and Data Analytics
Langues
Traduction automatique
Traduction automatique
De quoi avez-vous besoin de ma part pour commencer ?
Votre ensemble de données (CSV, Excel ou export de base de données) et une description claire de ce que vous souhaitez prédire ou classer. Si vous n’avez pas d’ensemble de données, contactez-moi d’abord.
Que faire si mon jeu de données est désordonné ou comporte des valeurs manquantes ?
Le nettoyage et le prétraitement de base des données sont inclus dans tous les packages. Pour des ensembles de données très non structurés ou volumineux, contactez-moi d’abord pour évaluer la portée.
Pourrai-je réentraîner le modèle avec de nouvelles données ?
Oui. Le notebook livré inclut le pipeline complet pour que vous puissiez le réentraîner avec des données mises à jour. La version Premium comprend une documentation sur la façon de procéder.
À quelle précision puis-je m'attendre ?
Cela dépend entièrement de la qualité de vos données et du type de problème. Je fournis toutes les métriques standard (accuracy, F1, précision, rappel, ROC-AUC) et je suis transparent sur les limitations du modèle.
Pouvez-vous déployer le modèle pour que d’autres puissent l’utiliser ?
Oui — Les versions Standard et Premium incluent le déploiement sur Hugging Face avec une interface Gradio. La version Premium comprend également un endpoint API pour intégration dans d’autres applications.
Travaillez-vous avec des données d’image, de texte ou tabulaires ?
Les trois. Vision par ordinateur (CNN), NLP (classification de texte, sentiment) et données tabulaires structurées (classification, régression, clustering).